
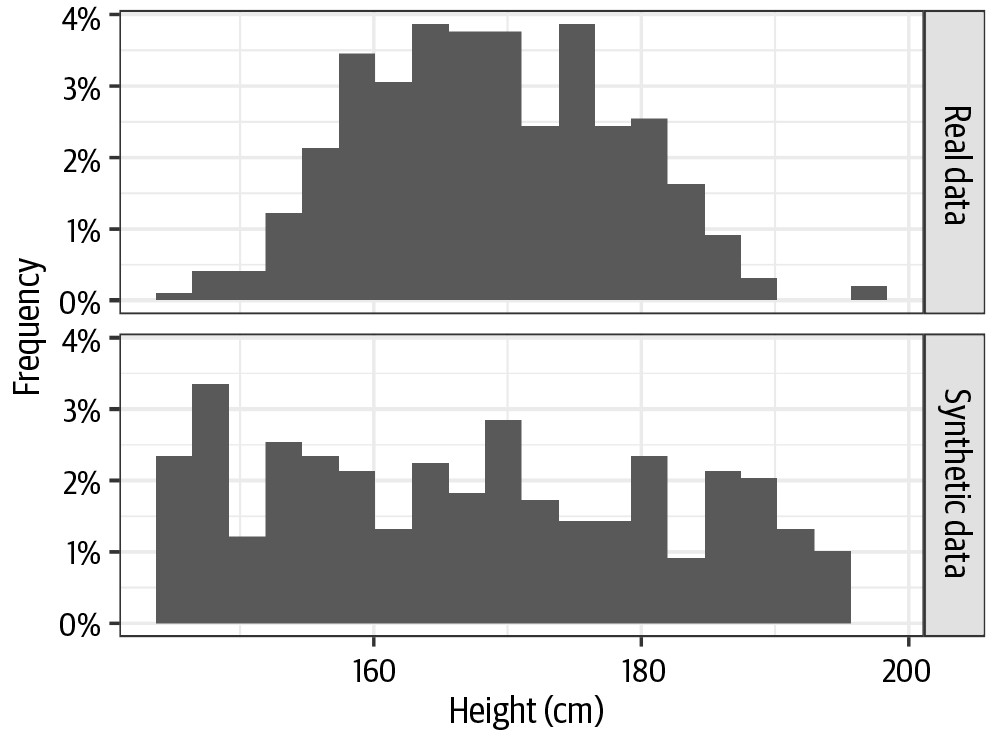
Synthetic data is revolutionizing the way businesses handle data privacy, model training, and cross-functional collaboration. By creating artificial datasets that maintain the statistical properties of real-world data, organizations can unlock innovation without breaching privacy or regulatory compliance.
This project explores the generation of synthetic data for enterprise applications, focusing specifically on:
Our primary dataset examples center around financial services and synthetic equity markets, drawing from publicly available resources and research by J.P. Morgan AI Research and Gretel.ai.
In addition, we used vibe coding (i.e., prompting an AI to write and execute the creation of code) to build an interactive website on the subject of synthetic data.
Artificially generated data that mimics the statistical properties of real data, used to replace or augment real-world datasets.
Why is it important for businesses?
Benefits:
Drawbacks:
Collect, clean, and analyze real data to understand its structure and biases.
Encodes real data into low-dimensional space and decodes to reconstruct similar data.

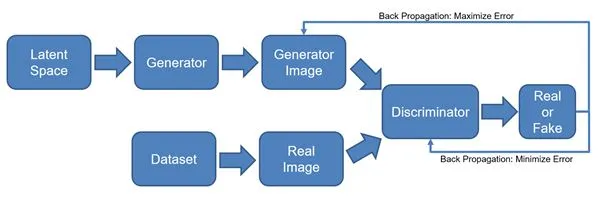
Two networks: generator vs. discriminator. Generator improves to fool the discriminator, leading to realistic outputs.
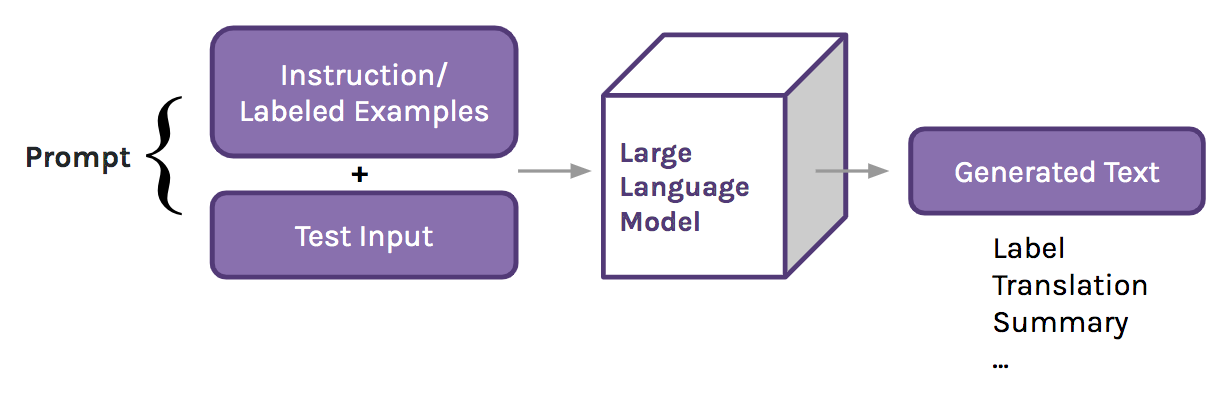
Used for generating synthetic text data. Trained on large corpora to replicate real-world linguistic structures.
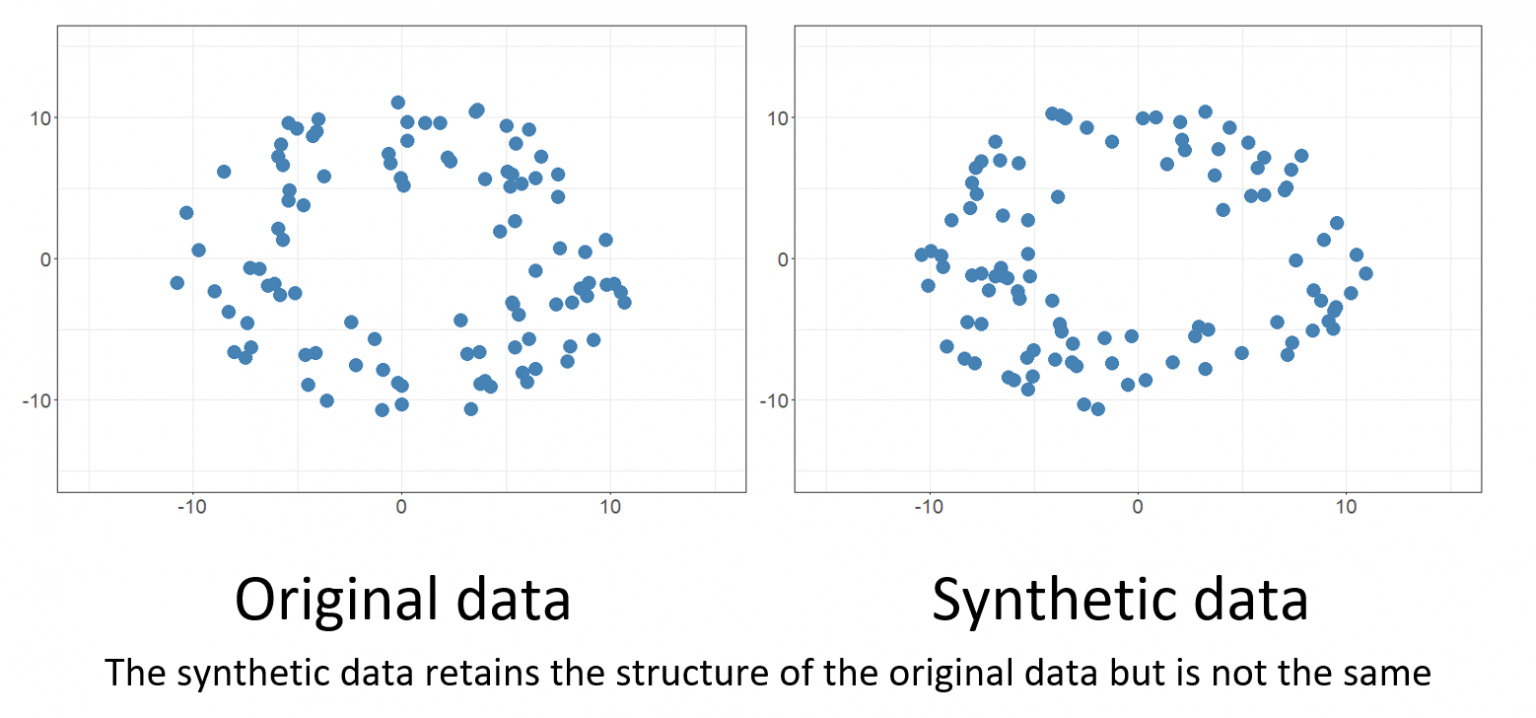
Generate synthetic data using your generator of choice. Then, analyze & compare metrics between your original data and the synthetic data.
The following code generates simple synthetic customer data by calling on a pre-established synthetic data library called Faker.
import random
import pandas as pd
import numpy as np
from faker import Faker
# Initialize the Faker library
fake = Faker()
# Set seeds for reproducibility
random.seed(42)
np.random.seed(42)
# Number of synthetic records
num_records = 1000
# Function to generate more realistic synthetic customer data
def generate_data(n):
data = []
for _ in range(n):
name = fake.name() # Generate full name
email = fake.email() # Generate fake email address
phone = fake.phone_number() # Generate fake phone number
city = fake.city() # Generate random city
state = fake.state() # Generate random U.S. state
age = random.randint(18, 70) # Random age
gender = random.choice(['Male', 'Female', 'Non-binary']) # Random gender
income = round(np.random.normal(60000, 15000), 2) # Normal distribution for annual income
product_interest = random.choice(['Fitness', 'Tech', 'Travel', 'Fashion', 'Home Decor', 'Beauty']) # Random interest category
purchased = np.random.choice([0, 1], p=[0.7, 0.3]) # 30% chance of having purchased
data.append([name, email, phone, city, state, age, gender, income, product_interest, purchased])
return data
# Define column names
columns = [
'Name', 'Email', 'Phone', 'City', 'State',
'Age', 'Gender', 'Annual_Income', 'Product_Interest', 'Purchased'
]
# Generate and store the data in a DataFrame
synthetic_data = pd.DataFrame(generate_data(num_records), columns=columns)
# Preview the first few rows
print(synthetic_data.head())
# Optional: Save to CSV
synthetic_data.to_csv('enhanced_synthetic_customer_data.csv', index=False)Synthetic sequences of banking actions (e.g., account opening, transfers, purchases)
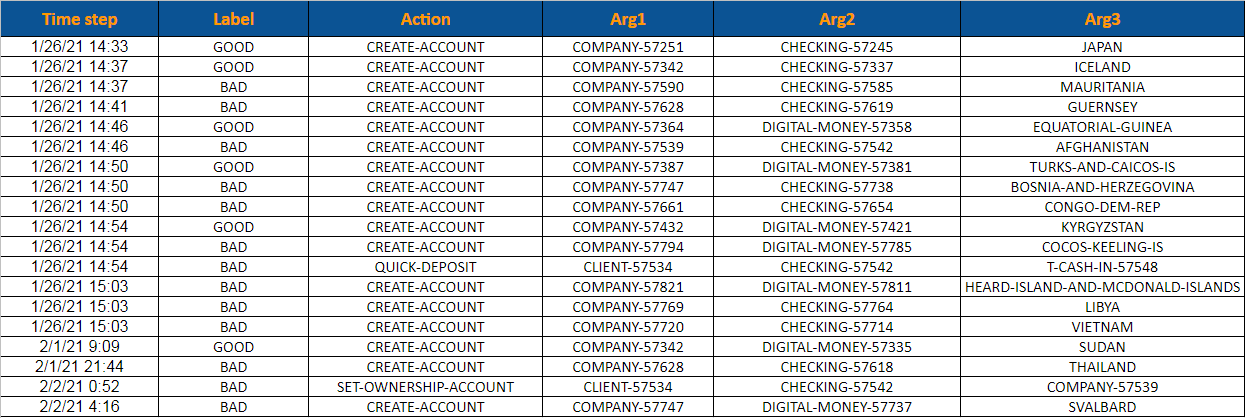
Simulated spot and option prices
- Based on Bloomberg market data
- Reconstructed using deep learning models

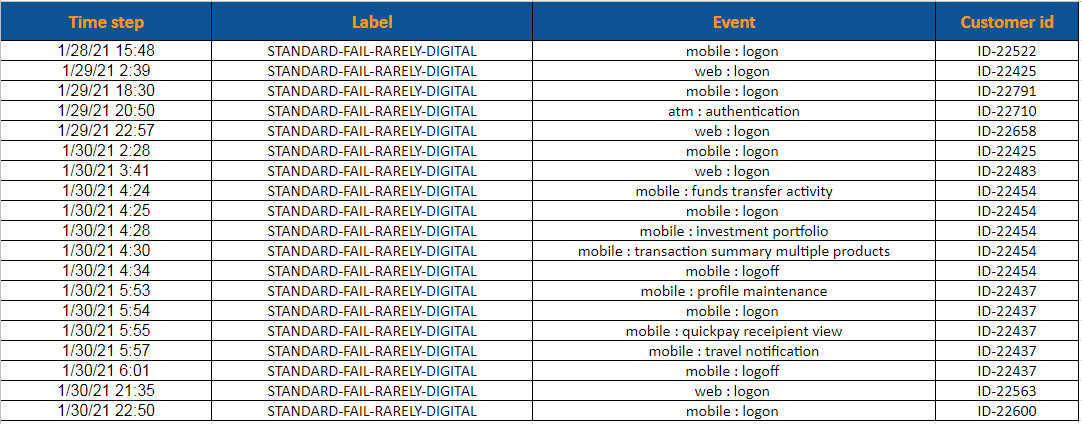
Sequences of retail banking actions like ATM withdrawals and app usage

1. ArXiv - Synthetic Data in Machine Learning
- Research Paper: https://arxiv.org/pdf/2205.03257
2. IBM - Variational Autoencoders
- Research: https://www.ibm.com/think/topics/variational-autoencoder
- Image Reference: IBM VAE Image
3. Medium - Packt - GAN Architecture
- Research: Medium GAN Article
- Image Reference: GAN Architecture Image
4. UK Government - Synthetic Data for ML
- Research: UK Gov Blog
- Image Reference: UK Gov Synthetic Data Image
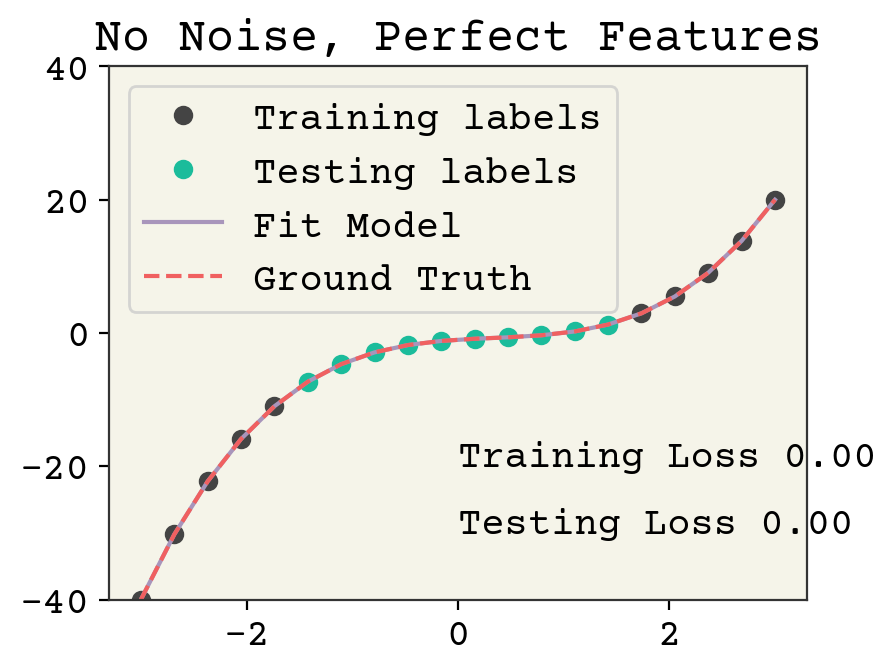
5. Regression Visualization
- Image Reference Only: Regression Plot Image
6. Medium - Underfitting vs. Overfitting
- Research: Medium Article
- Image Reference: Under/Overfitting Image
7. JPMorgan - Synthetic Data for Anti-Money Laundering
- Research: AML Article
- Image Reference: AML Data Image
8. O’Reilly - Practical Synthetic Data
- Research: O'Reilly Chapter
- Image Reference: O’Reilly Synthetic Data Image
9. The Gradient - LLMs & Linguistics
- Research: Gradient Article
- Image Reference: LLM Diagram Image
10. JPMorgan - Synthetic Equity Market Data
- Research: JPMorgan Equity Data
- Image Reference: Synthetic Equity Market Image
11. JPMorgan - Customer Journey Event Data
- Research: Customer Journey Article
- Image Reference: Customer Journey Event Image
12. Gretel AI - Synthetic Relational Databases
- Research: Gretel Blog
- Image Reference: Gretel Relational DB Image
This README is part of the MSBA Team 8 Final Project on Synthetic Data for Privacy-Preserving AI Development. For code, datasets, and demos, please refer to the repository directories.
{kind=link}
{kind=link}